Dataset Preparer (Beta)¶
Note
Dataset Preparer is still in beta version and might not be stable enough. You are welcome to try it out and report any issues to us.
One-click data preparation script¶
MMOCR provides a unified one-stop data preparation script prepare_dataset.py.
Only one line of command is needed to complete the data download, decompression, format conversion, and basic configure generation.
python tools/dataset_converters/prepare_dataset.py [-h] [--nproc NPROC] [--task {textdet,textrecog,textspotting,kie}] [--splits SPLITS [SPLITS ...]] [--lmdb] [--overwrite-cfg] [--dataset-zoo-path DATASET_ZOO_PATH] datasets [datasets ...]
| ARGS | Type | Description |
|---|---|---|
| dataset_name | str | (required) dataset name. |
| --nproc | int | Number of processes to be used. Defaults to 4. |
| --task | str | Convert the dataset to the format of a specified task supported by MMOCR. options are: 'textdet', 'textrecog', 'textspotting', and 'kie'. |
| --splits | str | Splits of the dataset to be prepared. Multiple splits can be accepted. Defaults to train val test. |
| --lmdb | str | Store the data in LMDB format. Only valid when the task is textrecog. |
| --overwrite-cfg | str | Whether to overwrite the dataset config file if it already exists in configs/{task}/_base_/datasets. |
| --dataset-zoo-path | str | Path to the dataset config file. If not specified, the default path is ./dataset_zoo. |
For example, the following command shows how to use the script to prepare the ICDAR2015 dataset for text detection task.
python tools/dataset_converters/prepare_dataset.py icdar2015 --task textdet --overwrite-cfg
Also, the script supports preparing multiple datasets at the same time. For example, the following command shows how to prepare the ICDAR2015 and TotalText datasets for text recognition task.
python tools/dataset_converters/prepare_dataset.py icdar2015 totaltext --task textrecog --overwrite-cfg
To check the supported datasets of Dataset Preparer, please refer to Dataset Zoo. Some of other datasets that need to be prepared manually are listed in Text Detection and Text Recognition.
For users in China, more datasets can be downloaded from the opensource dataset platform: OpenDataLab. After downloading the data, you can place the files listed in data_obtainer.save_name in data/cache and rerun the script.
Advanced Usage¶
LMDB Format¶
In text recognition tasks, we usually use LMDB format to store data to speed up data loading. When using the prepare_dataset.py script to prepare data, you can store data to the LMDB format by the --lmdb parameter. For example:
python tools/dataset_converters/prepare_dataset.py icdar2015 --task textrecog --lmdb
As soon as the dataset is prepared, Dataset Preparer will generate icdar2015_lmdb.py in the configs/textrecog/_base_/datasets/ directory. You can inherit this file and point the dataloader to the LMDB dataset. Moreover, the LMDB dataset needs to be loaded by LoadImageFromNDArray, thus you also need to modify pipeline.
For example, if we want to change the training set of configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py to icdar2015 generated before, we need to perform the following modifications:
Modify
configs/textrecog/crnn/crnn_mini-vgg_5e_mj.py:_base_ = [ '../_base_/datasets/icdar2015_lmdb.py', # point to icdar2015 lmdb dataset ... ] train_list = [_base_.icdar2015_lmdb_textrecog_train] ...
Modify
train_pipelineinconfigs/textrecog/crnn/_base_crnn_mini-vgg.py, changeLoadImageFromFiletoLoadImageFromNDArray:train_pipeline = [ dict( type='LoadImageFromNDArray', color_type='grayscale', file_client_args=file_client_args, ignore_empty=True, min_size=2), ... ]
Design¶
There are many OCR datasets with different languages, annotation formats, and scenarios. There are generally two ways to use these datasets: to quickly understand the relevant information about the dataset, or to use it to train models. To meet these two usage scenarios, MMOCR provides dataset automatic preparation scripts. The dataset automatic preparation script uses modular design, which greatly enhances scalability, and allows users to easily configure other public or private datasets. The configuration files for the dataset automatic preparation script are uniformly stored in the dataset_zoo/ directory. Users can find all the configuration files for the dataset preparation scripts officially supported by MMOCR in this directory. The directory structure of this folder is as follows:
dataset_zoo/
├── icdar2015
│ ├── metafile.yml
│ ├── sample_anno.md
│ ├── textdet.py
│ ├── textrecog.py
│ └── textspotting.py
└── wildreceipt
├── metafile.yml
├── sample_anno.md
├── kie.py
├── textdet.py
├── textrecog.py
└── textspotting.py
Dataset Usage¶
After decades of development, the OCR field has seen a series of related datasets emerge, often providing text annotation files in various styles, making it necessary for users to perform format conversion when using these datasets. Therefore, to facilitate dataset preparation for users, we have designed the Dataset Preparer to help users quickly prepare datasets in the format supported by MMOCR. For details, please refer to the Dataset Format document. The following figure shows a typical workflow for running the Dataset Preparer.
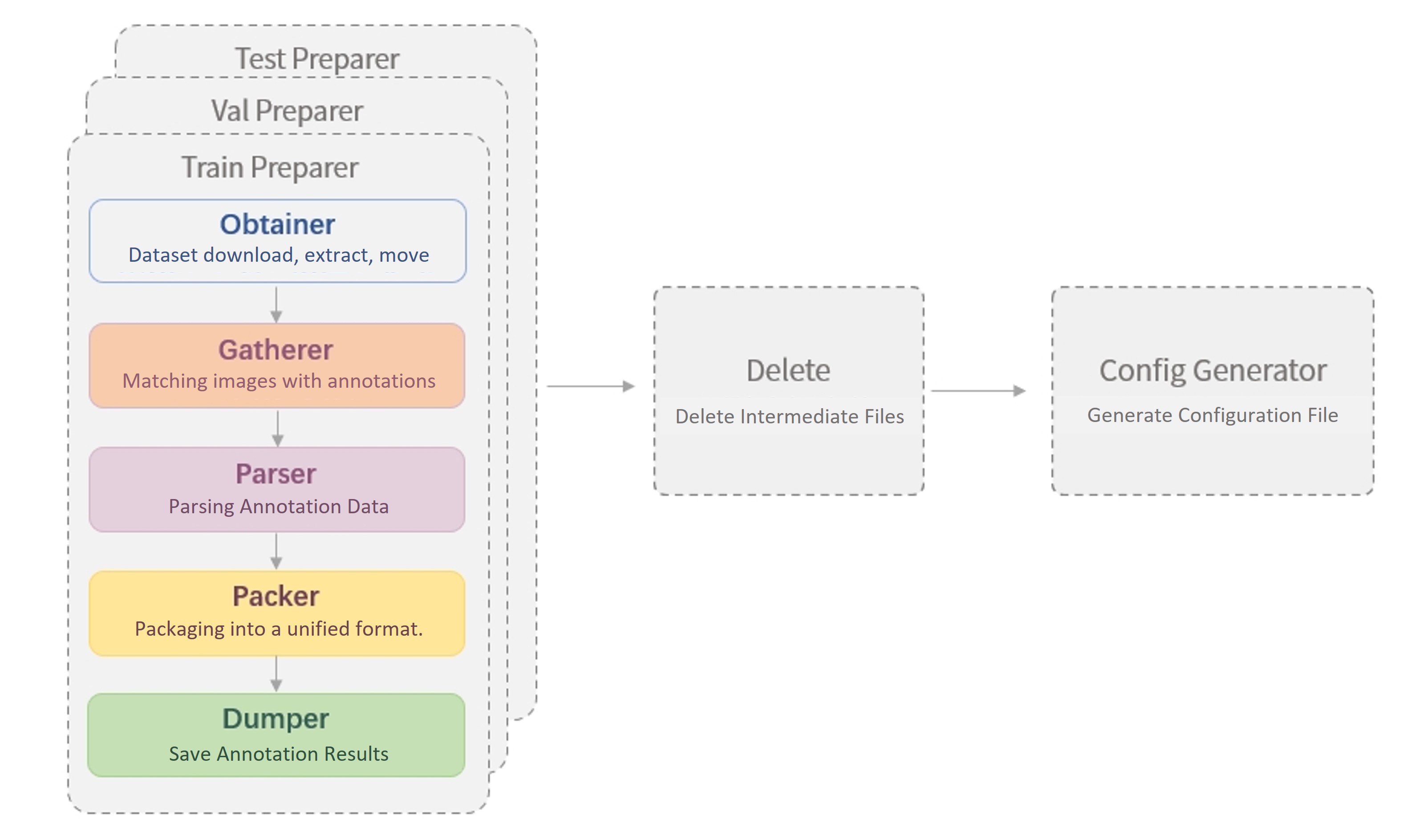
The figure shows that when running the Dataset Preparer, the following operations will be performed in sequence:
For the training set, validation set, and test set, the preparers will perform:
Dataset download, extraction, and movement (Obtainer)
Delete files (Delete)
Generate the configuration file for the data set (Config Generator).
To handle various types of datasets, MMOCR has designed each component as a plug-and-play module, and allows users to configure the dataset preparation process through configuration files located in dataset_zoo/. These configuration files are in Python format and can be used in the same way as other configuration files in MMOCR, as described in the Configuration File documentation.
In dataset_zoo/, each dataset has its own folder, and the configuration files are named after the task to distinguish different configurations under different tasks. Taking the text detection part of ICDAR2015 as an example, the sample configuration file dataset_zoo/icdar2015/textdet.py is shown below:
data_root = 'data/icdar2015'
cache_path = 'data/cache'
train_preparer = dict(
obtainer=dict(
type='NaiveDataObtainer',
cache_path=cache_path,
files=[
dict(
url='https://rrc.cvc.uab.es/downloads/ch4_training_images.zip',
save_name='ic15_textdet_train_img.zip',
md5='c51cbace155dcc4d98c8dd19d378f30d',
content=['image'],
mapping=[['ic15_textdet_train_img', 'textdet_imgs/train']]),
dict(
url='https://rrc.cvc.uab.es/downloads/'
'ch4_training_localization_transcription_gt.zip',
save_name='ic15_textdet_train_gt.zip',
md5='3bfaf1988960909014f7987d2343060b',
content=['annotation'],
mapping=[['ic15_textdet_train_gt', 'annotations/train']]),
]),
gatherer=dict(
type='PairGatherer',
img_suffixes=['.jpg', '.JPG'],
rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
parser=dict(type='ICDARTxtTextDetAnnParser', encoding='utf-8-sig'),
packer=dict(type='TextDetPacker'),
dumper=dict(type='JsonDumper'),
)
test_preparer = dict(
obtainer=dict(
type='NaiveDataObtainer',
cache_path=cache_path,
files=[
dict(
url='https://rrc.cvc.uab.es/downloads/ch4_test_images.zip',
save_name='ic15_textdet_test_img.zip',
md5='97e4c1ddcf074ffcc75feff2b63c35dd',
content=['image'],
mapping=[['ic15_textdet_test_img', 'textdet_imgs/test']]),
dict(
url='https://rrc.cvc.uab.es/downloads/'
'Challenge4_Test_Task4_GT.zip',
save_name='ic15_textdet_test_gt.zip',
md5='8bce173b06d164b98c357b0eb96ef430',
content=['annotation'],
mapping=[['ic15_textdet_test_gt', 'annotations/test']]),
]),
gatherer=dict(
type='PairGatherer',
img_suffixes=['.jpg', '.JPG'],
rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
parser=dict(type='ICDARTxtTextDetAnnParser', encoding='utf-8-sig'),
packer=dict(type='TextDetPacker'),
dumper=dict(type='JsonDumper'),
)
delete = ['annotations', 'ic15_textdet_test_img', 'ic15_textdet_train_img']
config_generator = dict(type='TextDetConfigGenerator')
Dataset download extraction and movement (Obtainer)¶
The obtainer module in Dataset Preparer is responsible for downloading, extracting, and moving the dataset. Currently, MMOCR only provides the NaiveDataObtainer. Generally speaking, the built-in NaiveDataObtainer is sufficient for downloading most datasets that can be accessed through direct links, and supports operations such as extraction, moving files, and renaming. However, MMOCR currently does not support automatically downloading datasets stored in resources that require login, such as Baidu or Google Drive. Here is a brief introduction to the NaiveDataObtainer.
| Field Name | Meaning |
|---|---|
| cache_path | Dataset cache path, used to store the compressed files downloaded during dataset preparation |
| data_root | Root directory where the dataset is stored |
| files | Dataset file list, used to describe the download information of the dataset |
The files field is a list, and each element in the list is a dictionary used to describe the download information of a dataset file. The table below shows the meaning of each field:
| Field Name | Meaning |
|---|---|
| url | Download link for the dataset file |
| save_name | Name used to save the dataset file |
| md5 (optional) | MD5 hash of the dataset file, used to check if the downloaded file is complete |
| split (optional) | Dataset split the file belongs to, such as train, test, etc., this field can be omitted |
| content (optional) | Content of the dataset file, such as image, annotation, etc., this field can be omitted |
| mapping (optional) | Decompression mapping of the dataset file, used to specify the storage location of the file after decompression, this field can be omitted |
The Dataset Preparer follows the following conventions:
Images of different types of datasets are moved to the corresponding category
{taskname}_imgs/{split}/folder, such astextdet_imgs/train/.For a annotation file containing annotation information for all images, the annotations are moved to
annotations/{split}.*file, such asannotations/train.json.For a annotation file containing annotation information for one image, all annotation files are moved to
annotations/{split}/folder, such asannotations/train/.For some other special cases, such as all training, testing, and validation images are in one folder, the images can be moved to a self-set folder, such as
{taskname}_imgs/imgs/, and the image storage location should be specified in the subsequentgatherermodule.
An example configuration is as follows:
obtainer=dict(
type='NaiveDataObtainer',
cache_path=cache_path,
files=[
dict(
url='https://rrc.cvc.uab.es/downloads/ch4_training_images.zip',
save_name='ic15_textdet_train_img.zip',
md5='c51cbace155dcc4d98c8dd19d378f30d',
content=['image'],
mapping=[['ic15_textdet_train_img', 'textdet_imgs/train']]),
dict(
url='https://rrc.cvc.uab.es/downloads/'
'ch4_training_localization_transcription_gt.zip',
save_name='ic15_textdet_train_gt.zip',
md5='3bfaf1988960909014f7987d2343060b',
content=['annotation'],
mapping=[['ic15_textdet_train_gt', 'annotations/train']]),
]),
Dataset collection (Gatherer)¶
The gatherer module traverses the files in the dataset directory, matches image files with their corresponding annotation files, and organizes a file list for the parser module to read. Therefore, it is necessary to know the matching rules between image files and annotation files in the current dataset. There are two commonly used annotation storage formats for OCR datasets: one is multiple annotation files corresponding to multiple images, and the other is a single annotation file corresponding to multiple images, for example:
Many-to-Many
├── {taskname}_imgs/{split}/img_img_1.jpg
├── annotations/{split}/gt_img_1.txt
├── {taskname}_imgs/{split}/img_2.jpg
├── annotations/{split}/gt_img_2.txt
├── {taskname}_imgs/{split}/img_3.JPG
├── annotations/{split}/gt_img_3.txt
One-to-Many
├── {taskname}/{split}/img_1.jpg
├── {taskname}/{split}/img_2.jpg
├── {taskname}/{split}/img_3.JPG
├── annotations/gt.txt
Specific design is as follows:
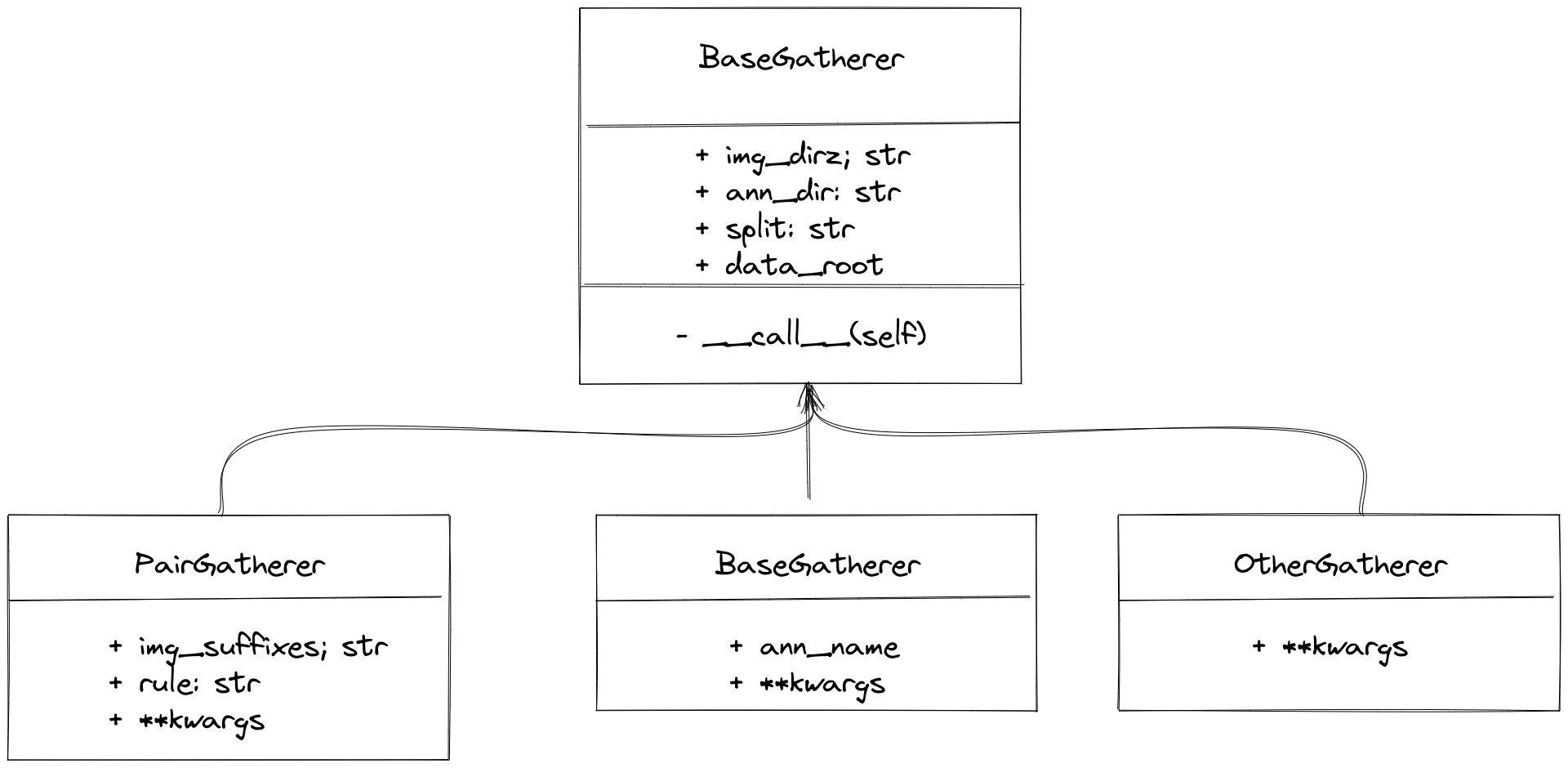
MMOCR has built-in PairGatherer and MonoGatherer to handle the two common cases mentioned above. PairGatherer is used for many-to-many situations, while MonoGatherer is used for one-to-many situations.
Note
To simplify processing, the gatherer assumes that the dataset’s images and annotations are stored separately in {taskname}_imgs/{split}/ and annotations/, respectively. In particular, for many-to-many situations, the annotation file needs to be placed in annotations/{split}.
In the many-to-many case,
PairGathererneeds to find the image files and corresponding annotation files according to a certain naming convention. First, the suffix of the image needs to be specified by theimg_suffixesparameter, as in the example aboveimg_suffixes=[.jpg,.JPG]. In addition, a pair of regular expressionsruleis used to specify the correspondence between the image and annotation files. For example,rule=[r'img_(\d+)\.([jJ][pP][gG])',r'gt_img_\1.txt']. The first regular expression is used to match the image file name,\d+is used to match the image sequence number, and([jJ][pP][gG])is used to match the image suffix. The second regular expression is used to match the annotation file name, where\1associates the matched image sequence number with the annotation file sequence number. An example configuration is:
gatherer=dict(
type='PairGatherer',
img_suffixes=['.jpg', '.JPG'],
rule=[r'img_(\d+)\.([jJ][pP][gG])', r'gt_img_\1.txt']),
For the case of one-to-many, it is usually simple, and the user only needs to specify the annotation file name. For example, for the training set configuration:
gatherer=dict(type='MonoGatherer', ann_name='train.txt'),
MMOCR has also made conventions on the return value of Gatherer. Gatherer returns a tuple with two elements. The first element is a list of image paths (including all image paths) or the folder containing all images. The second element is a list of annotation file paths (including all annotation file paths) or the path of the annotation file (the annotation file contains all image annotation information). Specifically, the return value of PairGatherer is (list of image paths, list of annotation file paths), as shown below:
(['{taskname}_imgs/{split}/img_1.jpg', '{taskname}_imgs/{split}/img_2.jpg', '{taskname}_imgs/{split}/img_3.JPG'],
['annotations/{split}/gt_img_1.txt', 'annotations/{split}/gt_img_2.txt', 'annotations/{split}/gt_img_3.txt'])
MonoGatherer returns a tuple containing the path to the image directory and the path to the annotation file, as follows:
('{taskname}/{split}', 'annotations/gt.txt')
Dataset parsing (Parser)¶
Parser is mainly used to parse the original annotation files. Since the original annotation formats vary greatly, MMOCR provides BaseParser as a base class, which users can inherit to implement their own Parser. In BaseParser, MMOCR has designed two interfaces: parse_files and parse_file, where the annotation parsing is conventionally carried out. For the two different input situations of Gatherer (many-to-many, one-to-many), the implementations of these two interfaces should be different.
BaseParserby default handles the many-to-many situation. Among them,parse_filesdistributes the data in parallel to multipleparse_fileprocesses, and eachparse_fileparses the annotation of a single image separately.For the one-to-many situation, the user needs to override
parse_filesto implement loading the annotation and returning standardized results.
The interface of BaseParser is defined as follows:
class BaseParser:
def __call__(self, img_paths, ann_paths):
return self.parse_files(img_paths, ann_paths)
def parse_files(self, img_paths: Union[List[str], str],
ann_paths: Union[List[str], str]) -> List[Tuple]:
samples = track_parallel_progress_multi_args(
self.parse_file, (img_paths, ann_paths), nproc=self.nproc)
return samples
@abstractmethod
def parse_file(self, img_path: str, ann_path: str) -> Tuple:
raise NotImplementedError
In order to ensure the uniformity of subsequent modules, MMOCR has made conventions for the return values of parse_files and parse_file. The return value of parse_file is a tuple, the first element of which is the image path, and the second element is the annotation information. The annotation information is a list, each element of which is a dictionary with the fields poly, text, and ignore, as shown below:
# An example of returned values:
(
'imgs/train/xxx.jpg',
[
dict(
poly=[0, 1, 1, 1, 1, 0, 0, 0],
text='hello',
ignore=False),
...
]
)
The output of parse_files is a list, and each element in the list is the return value of parse_file. An example is:
[
(
'imgs/train/xxx.jpg',
[
dict(
poly=[0, 1, 1, 1, 1, 0, 0, 0],
text='hello',
ignore=False),
...
]
),
...
]
Dataset Conversion (Packer)¶
Packer is mainly used to convert data into a unified annotation format, because the input data is the output of parsers and the format has been fixed. Therefore, the packer only needs to convert the input format into a unified annotation format for each task. Currently, MMOCR supports tasks such as text detection, text recognition, end-to-end OCR, and key information extraction, and MMOCR has a corresponding packer for each task, as shown below:
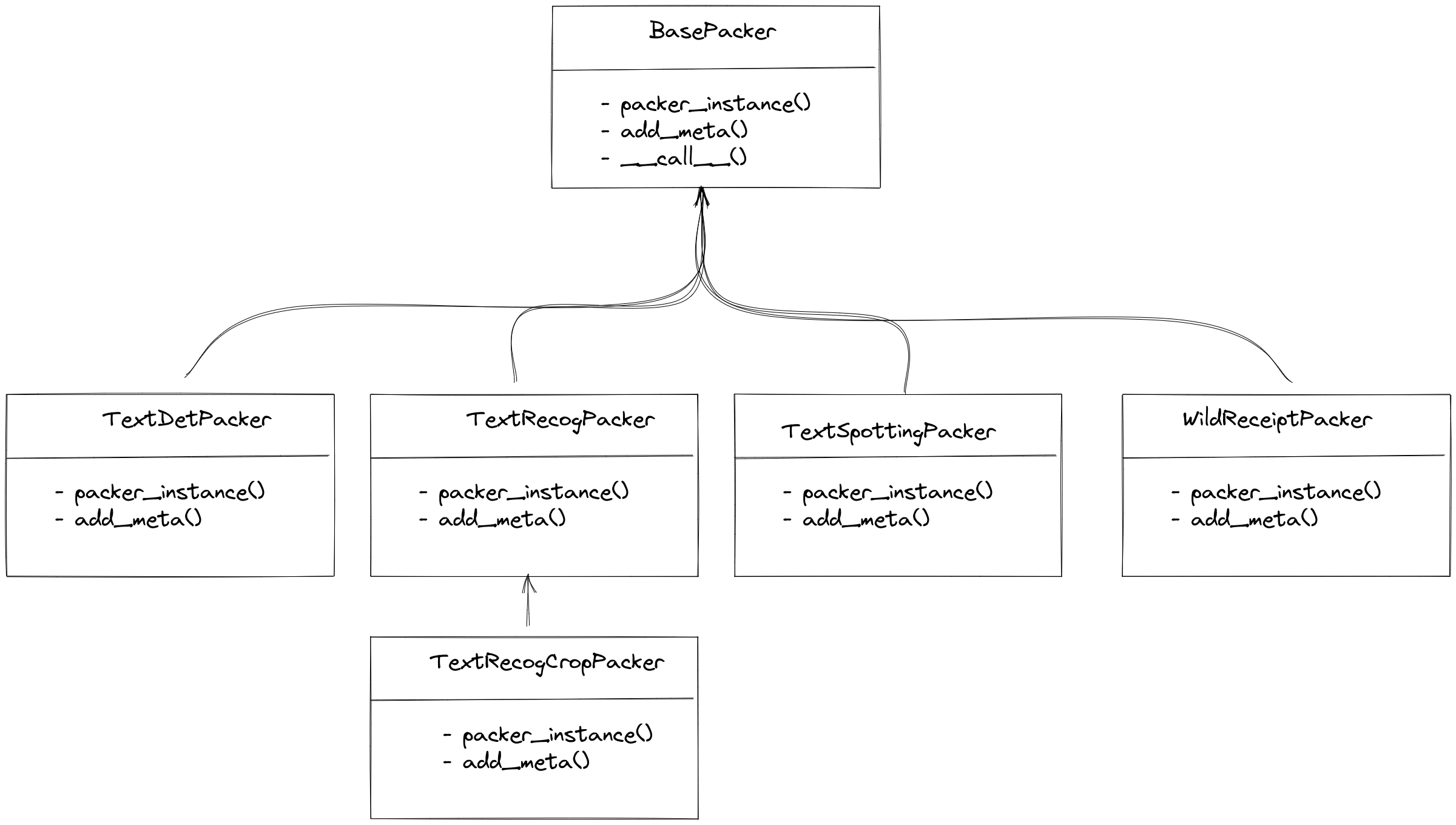
For text detection, end-to-end OCR, and key information extraction, MMOCR has a unique corresponding Packer. However, for text recognition, MMOCR provides two Packer options: TextRecogPacker and TextRecogCropPacker, due to the existence of two types of datasets:
Each image is a recognition sample, and the annotation information returned by the
parseris only adict(text='xxx'). In this case,TextRecogPackercan be used.The dataset does not crop text from the image, and it essentially contains end-to-end OCR annotations that include the position information of the text and the corresponding text information.
TextRecogCropPackerwill crop the text from the image and then convert it into the unified format for text recognition.
Annotation Saving (Dumper)¶
The dumper module is used to determine what format the data should be saved in. Currently, MMOCR supports JsonDumper, WildreceiptOpensetDumper, and TextRecogLMDBDumper. They are used to save data in the standard MMOCR JSON format, the Wildreceipt format, and the LMDB format commonly used in the academic community for text recognition, respectively.
Delete files (Delete)¶
When processing a dataset, temporary files that are not needed may be generated. Here, a list of such files or folders can be passed in, which will be deleted when the conversion is finished.
Generate the configuration file for the dataset (ConfigGenerator)¶
In order to automatically generate basic configuration files after preparing the dataset, MMOCR has implemented TextDetConfigGenerator, TextRecogConfigGenerator, and TextSpottingConfigGenerator for each task. The main parameters supported by these generators are as follows:
| Field Name | Meaning |
|---|---|
| data_root | Root directory where the dataset is stored. |
| train_anns | Path to the training set annotations in the configuration file. If not specified, it defaults to [dict(ann_file='{taskname}_train.json', dataset_postfix='']. |
| val_anns | Path to the validation set annotations in the configuration file. If not specified, it defaults to an empty string. |
| test_anns | Path to the test set annotations in the configuration file. If not specified, it defaults to [dict(ann_file='{taskname}_test.json', dataset_postfix='']. |
| config_path | Path to the directory where the configuration files for the algorithm are stored. The configuration generator will write the default configuration to {config_path}/{taskname}/_base_/datasets/{dataset_name}.py. If not specified, it defaults to configs/. |
After preparing all the files for the dataset, the configuration generator will automatically generate the basic configuration files required to call the dataset. Below is a minimal example of a TextDetConfigGenerator configuration:
config_generator = dict(type='TextDetConfigGenerator')
The generated file will be placed by default under configs/{task}/_base_/datasets/. In this example, the basic configuration file for the ICDAR 2015 dataset will be generated at configs/textdet/_base_/datasets/icdar2015.py.
icdar2015_textdet_data_root = 'data/icdar2015'
icdar2015_textdet_train = dict(
type='OCRDataset',
data_root=icdar2015_textdet_data_root,
ann_file='textdet_train.json',
filter_cfg=dict(filter_empty_gt=True, min_size=32),
pipeline=None)
icdar2015_textdet_test = dict(
type='OCRDataset',
data_root=icdar2015_textdet_data_root,
ann_file='textdet_test.json',
test_mode=True,
pipeline=None)
If the dataset is special and there are several variants of the annotations, the configuration generator also supports generating variables pointing to each variant in the base configuration. However, this requires users to differentiate them by using different dataset_postfix when setting up. For example, the ICDAR 2015 text recognition dataset has two annotation versions for the test set, the original version and the 1811 version, which can be specified in test_anns as follows:
config_generator = dict(
type='TextRecogConfigGenerator',
test_anns=[
dict(ann_file='textrecog_test.json'),
dict(dataset_postfix='857', ann_file='textrecog_test_857.json')
])
The configuration generator will generate the following configurations:
icdar2015_textrecog_data_root = 'data/icdar2015'
icdar2015_textrecog_train = dict(
type='OCRDataset',
data_root=icdar2015_textrecog_data_root,
ann_file='textrecog_train.json',
pipeline=None)
icdar2015_textrecog_test = dict(
type='OCRDataset',
data_root=icdar2015_textrecog_data_root,
ann_file='textrecog_test.json',
test_mode=True,
pipeline=None)
icdar2015_1811_textrecog_test = dict(
type='OCRDataset',
data_root=icdar2015_textrecog_data_root,
ann_file='textrecog_test_1811.json',
test_mode=True,
pipeline=None)
With this file, MMOCR can directly import this dataset into the dataloader from the model configuration file (the following sample is excerpted from configs/textdet/dbnet/dbnet_resnet18_fpnc_1200e_icdar2015.py):
_base_ = [
'../_base_/datasets/icdar2015.py',
# ...
]
# dataset settings
icdar2015_textdet_train = _base_.icdar2015_textdet_train
icdar2015_textdet_test = _base_.icdar2015_textdet_test
# ...
train_dataloader = dict(
dataset=icdar2015_textdet_train)
val_dataloader = dict(
dataset=icdar2015_textdet_test)
test_dataloader = val_dataloader
Note
By default, the configuration generator does not overwrite existing base configuration files unless the user manually specifies overwrite-cfg when running the script.
Adding a new dataset to Dataset Preparer¶
Adding Public Datasets¶
MMOCR has already supported many commonly used public datasets. If the dataset you want to use has not been supported yet and you are willing to contribute to the MMOCR open-source community, you can follow the steps below to add a new dataset.
In the following example, we will show you how to add the ICDAR2013 dataset step by step.
Adding metafile.yml¶
First, make sure that the dataset you want to add does not already exist in dataset_zoo/. Then, create a new folder named after the dataset you want to add, such as icdar2013/ (usually, use lowercase alphanumeric characters without symbols to name the dataset). In the icdar2013/ folder, create a metafile.yml file and fill in the basic information of the dataset according to the following template:
Name: 'Incidental Scene Text IC13'
Paper:
Title: ICDAR 2013 Robust Reading Competition
URL: https://www.imlab.jp/publication_data/1352/icdar_competition_report.pdf
Venue: ICDAR
Year: '2013'
BibTeX: '@inproceedings{karatzas2013icdar,
title={ICDAR 2013 robust reading competition},
author={Karatzas, Dimosthenis and Shafait, Faisal and Uchida, Seiichi and Iwamura, Masakazu and i Bigorda, Lluis Gomez and Mestre, Sergi Robles and Mas, Joan and Mota, David Fernandez and Almazan, Jon Almazan and De Las Heras, Lluis Pere},
booktitle={2013 12th international conference on document analysis and recognition},
pages={1484--1493},
year={2013},
organization={IEEE}}'
Data:
Website: https://rrc.cvc.uab.es/?ch=2
Language:
- English
Scene:
- Natural Scene
Granularity:
- Word
Tasks:
- textdet
- textrecog
- textspotting
License:
Type: N/A
Link: N/A
Format: .txt
Keywords:
- Horizontal
Add Annotation Examples¶
Finally, you can add an annotation example file sample_anno.md under the dataset_zoo/icdar2013/ directory to help the documentation script add annotation examples when generating documentation. The annotation example file is a Markdown file that typically contains the raw data format of a single sample. For example, the following code block shows a sample data file for the ICDAR2013 dataset:
**Text Detection**
```text
# train split
# x1 y1 x2 y2 "transcript"
158 128 411 181 "Footpath"
443 128 501 169 "To"
64 200 363 243 "Colchester"
# test split
# x1, y1, x2, y2, "transcript"
38, 43, 920, 215, "Tiredness"
275, 264, 665, 450, "kills"
0, 699, 77, 830, "A"
Add configuration files for corresponding tasks¶
In the dataset_zoo/icdar2013 directory, add a .py configuration file named after the task. For example, textdet.py, textrecog.py, textspotting.py, kie.py, etc. The configuration template is shown below:
data_root = ''
data_cache = 'data/cache'
train_prepare = dict(
obtainer=dict(
type='NaiveObtainer',
data_cache=data_cache,
files=[
dict(
url='xx',
md5='',
save_name='xxx',
mapping=list())
]),
gatherer=dict(type='xxxGatherer', **kwargs),
parser=dict(type='xxxParser', **kwargs),
packer=dict(type='TextxxxPacker'), # Packer for the task
dumper=dict(type='JsonDumper'),
)
test_prepare = dict(
obtainer=dict(
type='NaiveObtainer',
data_cache=data_cache,
files=[
dict(
url='xx',
md5='',
save_name='xxx',
mapping=list())
]),
gatherer=dict(type='xxxGatherer', **kwargs),
parser=dict(type='xxxParser', **kwargs),
packer=dict(type='TextxxxPacker'), # Packer for the task
dumper=dict(type='JsonDumper'),
)
Taking the file detection task as an example, let’s introduce the specific content of the configuration file. In general, users do not need to implement new obtainer, gatherer, packer, or dumper, but usually need to implement a new parser according to the annotation format of the dataset.
Regarding the configuration of obtainer, we will not go into detail here, and you can refer to Data set download, extraction, and movement (Obtainer).
For the gatherer, by observing the obtained ICDAR2013 dataset files, we found that each image has a corresponding .txt format annotation file:
data_root
├── textdet_imgs/train/
│ ├── img_1.jpg
│ ├── img_2.jpg
│ └── ...
├── annotations/train/
│ ├── gt_img_1.txt
│ ├── gt_img_2.txt
│ └── ...
Moreover, the name of each annotation file corresponds to the image: gt_img_1.txt corresponds to img_1.jpg, and so on. Therefore, PairGatherer can be used to match them.
gatherer=dict(
type='PairGatherer',
img_suffixes=['.jpg'],
rule=[r'(\w+)\.jpg', r'gt_\1.txt'])
The first regular expression in the rule is used to match the image file name, and the second regular expression is used to match the annotation file name. Here, (\w+) is used to match the image file name, and gt_\1.txt is used to match the annotation file name, where \1 represents the content matched by the first regular expression. That is, it replaces img_xx.jpg with gt_img_xx.txt.
Next, you need to implement a parser to parse the original annotation files into a standard format. Usually, before adding a new dataset, users can browse the details page of the supported datasets and check if there is a dataset with the same format. If there is, you can use the parser of that dataset directly. Otherwise, you need to implement a new format parser.
Data format parsers are stored in the mmocr/datasets/preparers/parsers directory. All parsers need to inherit from BaseParser and implement the parse_file or parse_files method. For more information, please refer to Parsing original annotations (Parser).
By observing the annotation files of the ICDAR2013 dataset:
158 128 411 181 "Footpath"
443 128 501 169 "To"
64 200 363 243 "Colchester"
542, 710, 938, 841, "break"
87, 884, 457, 1021, "could"
517, 919, 831, 1024, "save"
We found that the built-in ICDARTxtTextDetAnnParser already meets the requirements, so we can directly use this parser and configure it in the preparer.
parser=dict(
type='ICDARTxtTextDetAnnParser',
remove_strs=[',', '"'],
encoding='utf-8',
format='x1 y1 x2 y2 trans',
separator=' ',
mode='xyxy')
In the configuration for the ICDARTxtTextDetAnnParser, remove_strs=[',', '"'] is specified to remove extra quotes and commas in the annotation files. In the format section, x1 y1 x2 y2 trans indicates that each line in the annotation file contains four coordinates and a text content separated by spaces (separator=’ ‘). Also, mode is set to xyxy, which means that the coordinates in the annotation file are the coordinates of the top-left and bottom-right corners, so that ICDARTxtTextDetAnnParser can parse the annotations into a unified format.
For the packer, taking the file detection task as an example, its packer is TextDetPacker, and its configuration is as follows:
packer=dict(type='TextDetPacker')
Finally, specify the dumper, which is generally saved in json format. Its configuration is as follows:
dumper=dict(type='JsonDumper')
After the above configuration, the configuration file for the ICDAR2013 training set is as follows:
train_preparer = dict(
obtainer=dict(
type='NaiveDataObtainer',
cache_path=cache_path,
files=[
dict(
url='https://rrc.cvc.uab.es/downloads/'
'Challenge2_Training_Task12_Images.zip',
save_name='ic13_textdet_train_img.zip',
md5='a443b9649fda4229c9bc52751bad08fb',
content=['image'],
mapping=[['ic13_textdet_train_img', 'textdet_imgs/train']]),
dict(
url='https://rrc.cvc.uab.es/downloads/'
'Challenge2_Training_Task1_GT.zip',
save_name='ic13_textdet_train_gt.zip',
md5='f3a425284a66cd67f455d389c972cce4',
content=['annotation'],
mapping=[['ic13_textdet_train_gt', 'annotations/train']]),
]),
gatherer=dict(
type='PairGatherer',
img_suffixes=['.jpg'],
rule=[r'(\w+)\.jpg', r'gt_\1.txt']),
parser=dict(
type='ICDARTxtTextDetAnnParser',
remove_strs=[',', '"'],
format='x1 y1 x2 y2 trans',
separator=' ',
mode='xyxy'),
packer=dict(type='TextDetPacker'),
dumper=dict(type='JsonDumper'),
)
To automatically generate the basic configuration after the dataset is prepared, you also need to configure the corresponding task’s config_generator.
In this example, since it is a text detection task, you only need to set the generator to TextDetConfigGenerator.
config_generator = dict(type='TextDetConfigGenerator')
Use DataPreparer to prepare customized dataset¶
[Coming Soon]