Text Detection Models¶
DBNet¶
Real-time Scene Text Detection with Differentiable Binarization
Abstract¶
Recently, segmentation-based methods are quite popular in scene text detection, as the segmentation results can more accurately describe scene text of various shapes such as curve text. However, the post-processing of binarization is essential for segmentation-based detection, which converts probability maps produced by a segmentation method into bounding boxes/regions of text. In this paper, we propose a module named Differentiable Binarization (DB), which can perform the binarization process in a segmentation network. Optimized along with a DB module, a segmentation network can adaptively set the thresholds for binarization, which not only simplifies the post-processing but also enhances the performance of text detection. Based on a simple segmentation network, we validate the performance improvements of DB on five benchmark datasets, which consistently achieves state-of-the-art results, in terms of both detection accuracy and speed. In particular, with a light-weight backbone, the performance improvements by DB are significant so that we can look for an ideal tradeoff between detection accuracy and efficiency. Specifically, with a backbone of ResNet-18, our detector achieves an F-measure of 82.8, running at 62 FPS, on the MSRA-TD500 dataset.

Results and models¶
Citation¶
@article{Liao_Wan_Yao_Chen_Bai_2020,
title={Real-Time Scene Text Detection with Differentiable Binarization},
journal={Proceedings of the AAAI Conference on Artificial Intelligence},
author={Liao, Minghui and Wan, Zhaoyi and Yao, Cong and Chen, Kai and Bai, Xiang},
year={2020},
pages={11474-11481}}
DRRG¶
Deep relational reasoning graph network for arbitrary shape text detection
Abstract¶
Arbitrary shape text detection is a challenging task due to the high variety and complexity of scenes texts. In this paper, we propose a novel unified relational reasoning graph network for arbitrary shape text detection. In our method, an innovative local graph bridges a text proposal model via Convolutional Neural Network (CNN) and a deep relational reasoning network via Graph Convolutional Network (GCN), making our network end-to-end trainable. To be concrete, every text instance will be divided into a series of small rectangular components, and the geometry attributes (e.g., height, width, and orientation) of the small components will be estimated by our text proposal model. Given the geometry attributes, the local graph construction model can roughly establish linkages between different text components. For further reasoning and deducing the likelihood of linkages between the component and its neighbors, we adopt a graph-based network to perform deep relational reasoning on local graphs. Experiments on public available datasets demonstrate the state-of-the-art performance of our method.
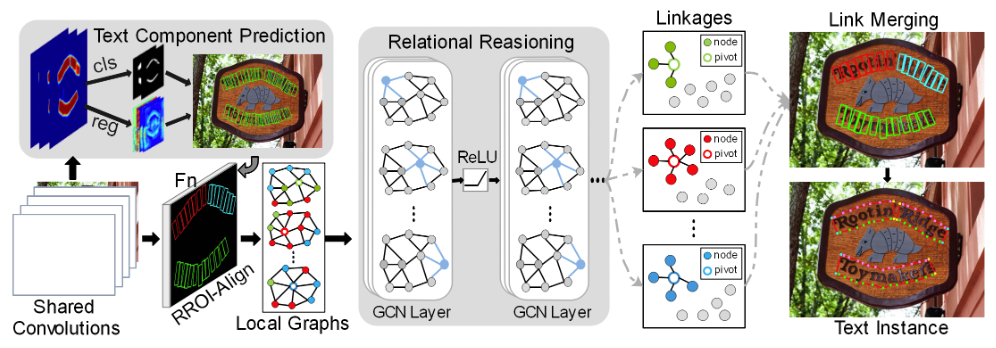
Results and models¶
CTW1500¶
| Method | Pretrained Model | Training set | Test set | ##epochs | Test size | Recall | Precision | Hmean | Download |
|---|---|---|---|---|---|---|---|---|---|
| DRRG | ImageNet | CTW1500 Train | CTW1500 Test | 1200 | 640 | 0.822 (0.791) | 0.858 (0.862) | 0.840 (0.825) | model \ log |
Note
We’ve upgraded our IoU backend from Polygon3 to shapely. There are some performance differences for some models due to the backends’ different logics to handle invalid polygons (more info here). New evaluation result is presented in brackets and new logs will be uploaded soon.
Citation¶
@article{zhang2020drrg,
title={Deep relational reasoning graph network for arbitrary shape text detection},
author={Zhang, Shi-Xue and Zhu, Xiaobin and Hou, Jie-Bo and Liu, Chang and Yang, Chun and Wang, Hongfa and Yin, Xu-Cheng},
booktitle={CVPR},
pages={9699-9708},
year={2020}
}
FCENet¶
Fourier Contour Embedding for Arbitrary-Shaped Text Detection
Abstract¶
One of the main challenges for arbitrary-shaped text detection is to design a good text instance representation that allows networks to learn diverse text geometry variances. Most of existing methods model text instances in image spatial domain via masks or contour point sequences in the Cartesian or the polar coordinate system. However, the mask representation might lead to expensive post-processing, while the point sequence one may have limited capability to model texts with highly-curved shapes. To tackle these problems, we model text instances in the Fourier domain and propose one novel Fourier Contour Embedding (FCE) method to represent arbitrary shaped text contours as compact signatures. We further construct FCENet with a backbone, feature pyramid networks (FPN) and a simple post-processing with the Inverse Fourier Transformation (IFT) and Non-Maximum Suppression (NMS). Different from previous methods, FCENet first predicts compact Fourier signatures of text instances, and then reconstructs text contours via IFT and NMS during test. Extensive experiments demonstrate that FCE is accurate and robust to fit contours of scene texts even with highly-curved shapes, and also validate the effectiveness and the good generalization of FCENet for arbitrary-shaped text detection. Furthermore, experimental results show that our FCENet is superior to the state-of-the-art (SOTA) methods on CTW1500 and Total-Text, especially on challenging highly-curved text subset.

Results and models¶
Citation¶
@InProceedings{zhu2021fourier,
title={Fourier Contour Embedding for Arbitrary-Shaped Text Detection},
author={Yiqin Zhu and Jianyong Chen and Lingyu Liang and Zhanghui Kuang and Lianwen Jin and Wayne Zhang},
year={2021},
booktitle = {CVPR}
}
Mask R-CNN¶
Abstract¶
We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition.

Results and models¶
CTW1500¶
| Method | Pretrained Model | Training set | Test set | ##epochs | Test size | Recall | Precision | Hmean | Download |
|---|---|---|---|---|---|---|---|---|---|
| MaskRCNN | ImageNet | CTW1500 Train | CTW1500 Test | 160 | 1600 | 0.753 | 0.712 | 0.732 | model | log |
ICDAR2015¶
| Method | Pretrained Model | Training set | Test set | ##epochs | Test size | Recall | Precision | Hmean | Download |
|---|---|---|---|---|---|---|---|---|---|
| MaskRCNN | ImageNet | ICDAR2015 Train | ICDAR2015 Test | 160 | 1920 | 0.783 | 0.872 | 0.825 | model | log |
ICDAR2017¶
| Method | Pretrained Model | Training set | Test set | ##epochs | Test size | Recall | Precision | Hmean | Download |
|---|---|---|---|---|---|---|---|---|---|
| MaskRCNN | ImageNet | ICDAR2017 Train | ICDAR2017 Val | 160 | 1600 | 0.754 | 0.827 | 0.789 | model | log |
Note
We tuned parameters with the techniques in Pyramid Mask Text Detector
Citation¶
@INPROCEEDINGS{8237584,
author={K. {He} and G. {Gkioxari} and P. {Dollár} and R. {Girshick}},
booktitle={2017 IEEE International Conference on Computer Vision (ICCV)},
title={Mask R-CNN},
year={2017},
pages={2980-2988},
doi={10.1109/ICCV.2017.322}}
PANet¶
Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network
Abstract¶
Scene text detection, an important step of scene text reading systems, has witnessed rapid development with convolutional neural networks. Nonetheless, two main challenges still exist and hamper its deployment to real-world applications. The first problem is the trade-off between speed and accuracy. The second one is to model the arbitrary-shaped text instance. Recently, some methods have been proposed to tackle arbitrary-shaped text detection, but they rarely take the speed of the entire pipeline into consideration, which may fall short in practical this http URL this paper, we propose an efficient and accurate arbitrary-shaped text detector, termed Pixel Aggregation Network (PAN), which is equipped with a low computational-cost segmentation head and a learnable post-processing. More specifically, the segmentation head is made up of Feature Pyramid Enhancement Module (FPEM) and Feature Fusion Module (FFM). FPEM is a cascadable U-shaped module, which can introduce multi-level information to guide the better segmentation. FFM can gather the features given by the FPEMs of different depths into a final feature for segmentation. The learnable post-processing is implemented by Pixel Aggregation (PA), which can precisely aggregate text pixels by predicted similarity vectors. Experiments on several standard benchmarks validate the superiority of the proposed PAN. It is worth noting that our method can achieve a competitive F-measure of 79.9% at 84.2 FPS on CTW1500.

Results and models¶
CTW1500¶
| Method | Pretrained Model | Training set | Test set | ##epochs | Test size | Recall | Precision | Hmean | Download |
|---|---|---|---|---|---|---|---|---|---|
| PANet | ImageNet | CTW1500 Train | CTW1500 Test | 600 | 640 | 0.776 (0.717) | 0.838 (0.835) | 0.806 (0.801) | model | log |
ICDAR2015¶
| Method | Pretrained Model | Training set | Test set | ##epochs | Test size | Recall | Precision | Hmean | Download |
|---|---|---|---|---|---|---|---|---|---|
| PANet | ImageNet | ICDAR2015 Train | ICDAR2015 Test | 600 | 736 | 0.734 (0.74) | 0.856 (0.86) | 0.791 (0.795) | model | log |
Note
We’ve upgraded our IoU backend from Polygon3 to shapely. There are some performance differences for some models due to the backends’ different logics to handle invalid polygons (more info here). New evaluation result is presented in brackets and new logs will be uploaded soon.
Citation¶
@inproceedings{WangXSZWLYS19,
author={Wenhai Wang and Enze Xie and Xiaoge Song and Yuhang Zang and Wenjia Wang and Tong Lu and Gang Yu and Chunhua Shen},
title={Efficient and Accurate Arbitrary-Shaped Text Detection With Pixel Aggregation Network},
booktitle={ICCV},
pages={8439--8448},
year={2019}
}
PSENet¶
Shape robust text detection with progressive scale expansion network
Abstract¶
Scene text detection has witnessed rapid progress especially with the recent development of convolutional neural networks. However, there still exists two challenges which prevent the algorithm into industry applications. On the one hand, most of the state-of-art algorithms require quadrangle bounding box which is in-accurate to locate the texts with arbitrary shape. On the other hand, two text instances which are close to each other may lead to a false detection which covers both instances. Traditionally, the segmentation-based approach can relieve the first problem but usually fail to solve the second challenge. To address these two challenges, in this paper, we propose a novel Progressive Scale Expansion Network (PSENet), which can precisely detect text instances with arbitrary shapes. More specifically, PSENet generates the different scale of kernels for each text instance, and gradually expands the minimal scale kernel to the text instance with the complete shape. Due to the fact that there are large geometrical margins among the minimal scale kernels, our method is effective to split the close text instances, making it easier to use segmentation-based methods to detect arbitrary-shaped text instances. Extensive experiments on CTW1500, Total-Text, ICDAR 2015 and ICDAR 2017 MLT validate the effectiveness of PSENet. Notably, on CTW1500, a dataset full of long curve texts, PSENet achieves a F-measure of 74.3% at 27 FPS, and our best F-measure (82.2%) outperforms state-of-art algorithms by 6.6%. The code will be released in the future.

Results and models¶
CTW1500¶
| Method | Backbone | Extra Data | Training set | Test set | ##epochs | Test size | Recall | Precision | Hmean | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| PSENet-4s | ResNet50 | - | CTW1500 Train | CTW1500 Test | 600 | 1280 | 0.728 (0.717) | 0.849 (0.852) | 0.784 (0.779) | model | log |
ICDAR2015¶
| Method | Backbone | Extra Data | Training set | Test set | ##epochs | Test size | Recall | Precision | Hmean | Download |
|---|---|---|---|---|---|---|---|---|---|---|
| PSENet-4s | ResNet50 | - | IC15 Train | IC15 Test | 600 | 2240 | 0.784 (0.753) | 0.831 (0.867) | 0.807 (0.806) | model | log |
| PSENet-4s | ResNet50 | pretrain on IC17 MLT model | IC15 Train | IC15 Test | 600 | 2240 | 0.834 | 0.861 | 0.847 | model | log |
Note
We’ve upgraded our IoU backend from Polygon3 to shapely. There are some performance differences for some models due to the backends’ different logics to handle invalid polygons (more info here). New evaluation result is presented in brackets and new logs will be uploaded soon.
Citation¶
@inproceedings{wang2019shape,
title={Shape robust text detection with progressive scale expansion network},
author={Wang, Wenhai and Xie, Enze and Li, Xiang and Hou, Wenbo and Lu, Tong and Yu, Gang and Shao, Shuai},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={9336--9345},
year={2019}
}
Textsnake¶
TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes
Abstract¶
Driven by deep neural networks and large scale datasets, scene text detection methods have progressed substantially over the past years, continuously refreshing the performance records on various standard benchmarks. However, limited by the representations (axis-aligned rectangles, rotated rectangles or quadrangles) adopted to describe text, existing methods may fall short when dealing with much more free-form text instances, such as curved text, which are actually very common in real-world scenarios. To tackle this problem, we propose a more flexible representation for scene text, termed as TextSnake, which is able to effectively represent text instances in horizontal, oriented and curved forms. In TextSnake, a text instance is described as a sequence of ordered, overlapping disks centered at symmetric axes, each of which is associated with potentially variable radius and orientation. Such geometry attributes are estimated via a Fully Convolutional Network (FCN) model. In experiments, the text detector based on TextSnake achieves state-of-the-art or comparable performance on Total-Text and SCUT-CTW1500, the two newly published benchmarks with special emphasis on curved text in natural images, as well as the widely-used datasets ICDAR 2015 and MSRA-TD500. Specifically, TextSnake outperforms the baseline on Total-Text by more than 40% in F-measure.

Results and models¶
Citation¶
@article{long2018textsnake,
title={TextSnake: A Flexible Representation for Detecting Text of Arbitrary Shapes},
author={Long, Shangbang and Ruan, Jiaqiang and Zhang, Wenjie and He, Xin and Wu, Wenhao and Yao, Cong},
booktitle={ECCV},
pages={20-36},
year={2018}
}