文本识别模型¶
ABINet¶
Abstract¶
Linguistic knowledge is of great benefit to scene text recognition. However, how to effectively model linguistic rules in end-to-end deep networks remains a research challenge. In this paper, we argue that the limited capacity of language models comes from: 1) implicitly language modeling; 2) unidirectional feature representation; and 3) language model with noise input. Correspondingly, we propose an autonomous, bidirectional and iterative ABINet for scene text recognition. Firstly, the autonomous suggests to block gradient flow between vision and language models to enforce explicitly language modeling. Secondly, a novel bidirectional cloze network (BCN) as the language model is proposed based on bidirectional feature representation. Thirdly, we propose an execution manner of iterative correction for language model which can effectively alleviate the impact of noise input. Additionally, based on the ensemble of iterative predictions, we propose a self-training method which can learn from unlabeled images effectively. Extensive experiments indicate that ABINet has superiority on low-quality images and achieves state-of-the-art results on several mainstream benchmarks. Besides, the ABINet trained with ensemble self-training shows promising improvement in realizing human-level recognition.

Dataset¶
Train Dataset¶
| trainset | instance_num | repeat_num | note |
|---|---|---|---|
| Syn90k | 8919273 | 1 | synth |
| SynthText | 7239272 | 1 | alphanumeric |
Test Dataset¶
| testset | instance_num | note |
|---|---|---|
| IIIT5K | 3000 | regular |
| SVT | 647 | regular |
| IC13 | 1015 | regular |
| IC15 | 2077 | irregular |
| SVTP | 645 | irregular |
| CT80 | 288 | irregular |
Results and models¶
| methods | pretrained | Regular Text | Irregular Text | download | ||||
|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | |||
| ABINet-Vision | - | 0.9523 | 0.9196 | 0.9369 | 0.7896 | 0.8403 | 0.8437 | model | log |
| ABINet-Vision-TTA | - | 0.9523 | 0.9196 | 0.9360 | 0.8175 | 0.8450 | 0.8542 | |
| ABINet | Pretrained | 0.9603 | 0.9397 | 0.9557 | 0.8146 | 0.8868 | 0.8785 | model | log |
| ABINet-TTA | Pretrained | 0.9597 | 0.9397 | 0.9527 | 0.8426 | 0.8930 | 0.8854 |
注解
ABINet allows its encoder to run and be trained without decoder and fuser. Its encoder is designed to recognize texts as a stand-alone model and therefore can work as an independent text recognizer. We release it as ABINet-Vision.
Facts about the pretrained model: MMOCR does not have a systematic pipeline to pretrain the language model (LM) yet, thus the weights of LM are converted from the official pretrained model. The weights of ABINet-Vision are directly used as the vision model of ABINet.
We also provide ABINet trained on Union14M
Evaluated on six common benchmarks
| methods | pretrained | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||||
| ABINet-Vision | - | 0.9730 | 0.9645 | 0.9552 | 0.8536 | 0.8977 | 0.9479 | model |
Evaluated on Union14M-Benchmark
| Methods | Unsolved Challenges | Additional Challenges | General | download | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Curve | Multi-Oriented | Artistic | Contextless | Salient | Multi-Words | Incomplete | General | |||
| ABINet-Vision | 0.750 | 0.615 | 0.653 | 0.711 | 0.729 | 0.591 | 0.026 | 0.794 | model |
Citation¶
@article{fang2021read,
title={Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition},
author={Fang, Shancheng and Xie, Hongtao and Wang, Yuxin and Mao, Zhendong and Zhang, Yongdong},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2021}
}
ASTER¶
ASTER: An Attentional Scene Text Recognizer with Flexible Rectification
Abstract¶
A challenging aspect of scene text recognition is to handle text with distortions or irregular layout. In particular, perspective text and curved text are common in natural scenes and are difficult to recognize. In this work, we introduce ASTER, an end-to-end neural network model that comprises a rectification network and a recognition network. The rectification network adaptively transforms an input image into a new one, rectifying the text in it. It is powered by a flexible Thin-Plate Spline transformation which handles a variety of text irregularities and is trained without human annotations. The recognition network is an attentional sequence-to-sequence model that predicts a character sequence directly from the rectified image. The whole model is trained end to end, requiring only images and their groundtruth text. Through extensive experiments, we verify the effectiveness of the rectification and demonstrate the state-of-the-art recognition performance of ASTER. Furthermore, we demonstrate that ASTER is a powerful component in end-to-end recognition systems, for its ability to enhance the detector.

Dataset¶
Train Dataset¶
| trainset | instance_num | repeat_num | note |
|---|---|---|---|
| Syn90k | 8919273 | 1 | synth |
| SynthText | 7239272 | 1 | alphanumeric |
Test Dataset¶
| testset | instance_num | note |
|---|---|---|
| IIIT5K | 3000 | regular |
| SVT | 647 | regular |
| IC13 | 1015 | regular |
| IC15 | 2077 | irregular |
| SVTP | 645 | irregular |
| CT80 | 288 | irregular |
Results and models¶
| Methods | Backbone | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||||
| ASTER | ResNet45 | 0.9357 | 0.8949 | 0.9281 | 0.7665 | 0.8062 | 0.8507 | model | log | |
| ASTER-TTA | ResNet45 | 0.9337 | 0.8949 | 0.9251 | 0.7925 | 0.8109 | 0.8507 |
We also provide ASTER trained on Union14M
Evaluated on six common benchmarks
| Methods | pretrained | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||||
| ASTER | - | 0.9437 | 0.8903 | 0.9360 | 0.7857 | 0.8093 | 0.9097 | model |
Evaluated on Union14M-Benchmark
| Methods | Unsolved Challenges | Additional Challenges | General | download | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Curve | Multi-Oriented | Artistic | Contextless | Salient | Multi-Words | Incomplete | General | |||
| ASTER | 0.384 | 0.130 | 0.418 | 0.529 | 0.319 | 0.498 | 0.013 | 0.667 | model |
Citation¶
@article{shi2018aster,
title={Aster: An attentional scene text recognizer with flexible rectification},
author={Shi, Baoguang and Yang, Mingkun and Wang, Xinggang and Lyu, Pengyuan and Yao, Cong and Bai, Xiang},
journal={IEEE transactions on pattern analysis and machine intelligence},
volume={41},
number={9},
pages={2035--2048},
year={2018},
publisher={IEEE}
}
CRNN¶
Abstract¶
Image-based sequence recognition has been a long-standing research topic in computer vision. In this paper, we investigate the problem of scene text recognition, which is among the most important and challenging tasks in image-based sequence recognition. A novel neural network architecture, which integrates feature extraction, sequence modeling and transcription into a unified framework, is proposed. Compared with previous systems for scene text recognition, the proposed architecture possesses four distinctive properties: (1) It is end-to-end trainable, in contrast to most of the existing algorithms whose components are separately trained and tuned. (2) It naturally handles sequences in arbitrary lengths, involving no character segmentation or horizontal scale normalization. (3) It is not confined to any predefined lexicon and achieves remarkable performances in both lexicon-free and lexicon-based scene text recognition tasks. (4) It generates an effective yet much smaller model, which is more practical for real-world application scenarios. The experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets, demonstrate the superiority of the proposed algorithm over the prior arts. Moreover, the proposed algorithm performs well in the task of image-based music score recognition, which evidently verifies the generality of it.

Dataset¶
Train Dataset¶
| trainset | instance_num | repeat_num | note |
|---|---|---|---|
| Syn90k | 8919273 | 1 | synth |
Test Dataset¶
| testset | instance_num | note |
|---|---|---|
| IIIT5K | 3000 | regular |
| SVT | 647 | regular |
| IC13 | 1015 | regular |
| IC15 | 2077 | irregular |
| SVTP | 645 | irregular |
| CT80 | 288 | irregular |
Results and models¶
| methods | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|
| methods | IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||
| CRNN | 0.8053 | 0.7991 | 0.8739 | 0.5571 | 0.6093 | 0.5694 | model | log | |
| CRNN-TTA | 0.8013 | 0.7975 | 0.8631 | 0.5763 | 0.6093 | 0.5764 | model | log |
Citation¶
@article{shi2016end,
title={An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition},
author={Shi, Baoguang and Bai, Xiang and Yao, Cong},
journal={IEEE transactions on pattern analysis and machine intelligence},
year={2016}
}
MAERec¶
Revisiting Scene Text Recognition: A Data Perspective
Abstract¶
This paper aims to re-assess scene text recognition (STR) from a data-oriented perspective. We begin by revisiting the six commonly used benchmarks in STR and observe a trend of performance saturation, whereby only 2.91% of the benchmark images cannot be accurately recognized by an ensemble of 13 representative models. While these results are impressive and suggest that STR could be considered solved, however, we argue that this is primarily due to the less challenging nature of the common benchmarks, thus concealing the underlying issues that STR faces. To this end, we consolidate a large-scale real STR dataset, namely Union14M, which comprises 4 million labeled images and 10 million unlabeled images, to assess the performance of STR models in more complex real-world scenarios. Our experiments demonstrate that the 13 models can only achieve an average accuracy of 66.53% on the 4 million labeled images, indicating that STR still faces numerous challenges in the real world. By analyzing the error patterns of the 13 models, we identify seven open challenges in STR and develop a challenge-driven benchmark consisting of eight distinct subsets to facilitate further progress in the field. Our exploration demonstrates that STR is far from being solved and leveraging data may be a promising solution. In this regard, we find that utilizing the 10 million unlabeled images through self-supervised pre-training can significantly improve the robustness of STR model in real-world scenarios and leads to state-of-the-art performance.
Dataset¶
Test Dataset¶
On six common benchmarks
| testset | instance_num | type |
|---|---|---|
| IIIT5K | 3000 | regular |
| SVT | 647 | regular |
| IC13 | 1015 | regular |
| IC15 | 2077 | irregular |
| SVTP | 645 | irregular |
| CT80 | 288 | irregular |
On Union14M-Benchmark
| testset | instance_num | type |
|---|---|---|
| Artistic | 900 | Unsolved Challenge |
| Curve | 2426 | Unsolved Challenge |
| Multi-Oriented | 1369 | Unsolved Challenge |
| Contextless | 779 | Additional Challenge |
| Multi-Words | 829 | Additional Challenge |
| Salient | 1585 | Additional Challenge |
| Incomplete | 1495 | Additional Challenge |
| General | 400,000 | - |
Results and Models¶
Evaluated on six common benchmarks
| Methods | Backbone | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||||
| MAERec-S | ViT-Small (Pretrained on Union14M-U) | 98.0 | 97.6 | 96.8 | 87.1 | 93.2 | 97.9 | model | |
| MAERec-B | ViT-Base (Pretrained on Union14M-U) | 98.5 | 98.1 | 97.8 | 89.5 | 94.4 | 98.6 | model |
Evaluated on Union14M-Benchmark
| Methods | Backbone | Unsolved Challenges | Additional Challenges | General | download | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Curve | Multi-Oriented | Artistic | Contextless | Salient | Multi-Words | Incomplete | General | ||||
| MAERec-S | ViT-Small (Pretrained on Union14M-U) | 81.4 | 71.4 | 72.0 | 82.0 | 78.5 | 82.4 | 2.7 | 82.5 | model | |
| MAERec-B | ViT-Base (Pretrained on Union14M-U) | 88.8 | 83.9 | 80.0 | 85.5 | 84.9 | 87.5 | 2.6 | 85.8 | model |
To train with MAERec, you need to download pretrained ViT weight and load it in the config file. Check here for instructions
Citation¶
@misc{jiang2023revisiting,
title={Revisiting Scene Text Recognition: A Data Perspective},
author={Qing Jiang and Jiapeng Wang and Dezhi Peng and Chongyu Liu and Lianwen Jin},
year={2023},
eprint={2307.08723},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
MASTER¶
MASTER: Multi-aspect non-local network for scene text recognition
Abstract¶
Attention-based scene text recognizers have gained huge success, which leverages a more compact intermediate representation to learn 1d- or 2d- attention by a RNN-based encoder-decoder architecture. However, such methods suffer from attention-drift problem because high similarity among encoded features leads to attention confusion under the RNN-based local attention mechanism. Moreover, RNN-based methods have low efficiency due to poor parallelization. To overcome these problems, we propose the MASTER, a self-attention based scene text recognizer that (1) not only encodes the input-output attention but also learns self-attention which encodes feature-feature and target-target relationships inside the encoder and decoder and (2) learns a more powerful and robust intermediate representation to spatial distortion, and (3) owns a great training efficiency because of high training parallelization and a high-speed inference because of an efficient memory-cache mechanism. Extensive experiments on various benchmarks demonstrate the superior performance of our MASTER on both regular and irregular scene text.

Dataset¶
Train Dataset¶
| trainset | instance_num | repeat_num | source |
|---|---|---|---|
| SynthText | 7266686 | 1 | synth |
| SynthAdd | 1216889 | 1 | synth |
| Syn90k | 8919273 | 1 | synth |
Test Dataset¶
| testset | instance_num | type |
|---|---|---|
| IIIT5K | 3000 | regular |
| SVT | 647 | regular |
| IC13 | 1015 | regular |
| IC15 | 2077 | irregular |
| SVTP | 645 | irregular |
| CT80 | 288 | irregular |
Results and Models¶
| Methods | Backbone | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||||
| MASTER | R31-GCAModule | 0.9490 | 0.8887 | 0.9517 | 0.7650 | 0.8465 | 0.8889 | model | log | |
| MASTER-TTA | R31-GCAModule | 0.9450 | 0.8887 | 0.9478 | 0.7906 | 0.8481 | 0.8958 |
Citation¶
@article{Lu2021MASTER,
title={MASTER: Multi-Aspect Non-local Network for Scene Text Recognition},
author={Ning Lu and Wenwen Yu and Xianbiao Qi and Yihao Chen and Ping Gong and Rong Xiao and Xiang Bai},
journal={Pattern Recognition},
year={2021}
}
NRTR¶
NRTR: A No-Recurrence Sequence-to-Sequence Model For Scene Text Recognition
Abstract¶
Scene text recognition has attracted a great many researches due to its importance to various applications. Existing methods mainly adopt recurrence or convolution based networks. Though have obtained good performance, these methods still suffer from two limitations: slow training speed due to the internal recurrence of RNNs, and high complexity due to stacked convolutional layers for long-term feature extraction. This paper, for the first time, proposes a no-recurrence sequence-to-sequence text recognizer, named NRTR, that dispenses with recurrences and convolutions entirely. NRTR follows the encoder-decoder paradigm, where the encoder uses stacked self-attention to extract image features, and the decoder applies stacked self-attention to recognize texts based on encoder output. NRTR relies solely on self-attention mechanism thus could be trained with more parallelization and less complexity. Considering scene image has large variation in text and background, we further design a modality-transform block to effectively transform 2D input images to 1D sequences, combined with the encoder to extract more discriminative features. NRTR achieves state-of-the-art or highly competitive performance on both regular and irregular benchmarks, while requires only a small fraction of training time compared to the best model from the literature (at least 8 times faster).

Dataset¶
Train Dataset¶
| trainset | instance_num | repeat_num | source |
|---|---|---|---|
| SynthText | 7266686 | 1 | synth |
| Syn90k | 8919273 | 1 | synth |
Test Dataset¶
| testset | instance_num | type |
|---|---|---|
| IIIT5K | 3000 | regular |
| SVT | 647 | regular |
| IC13 | 1015 | regular |
| IC15 | 2077 | irregular |
| SVTP | 645 | irregular |
| CT80 | 288 | irregular |
Results and Models¶
| Methods | Backbone | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||||
| NRTR | NRTRModalityTransform | 0.9147 | 0.8841 | 0.9369 | 0.7246 | 0.7783 | 0.7500 | model | log | |
| NRTR-TTA | NRTRModalityTransform | 0.9123 | 0.8825 | 0.9310 | 0.7492 | 0.7798 | 0.7535 | ||
| NRTR | R31-1/8-1/4 | 0.9483 | 0.8918 | 0.9507 | 0.7578 | 0.8016 | 0.8889 | model | log | |
| NRTR-TTA | R31-1/8-1/4 | 0.9443 | 0.8903 | 0.9478 | 0.7790 | 0.8078 | 0.8854 | ||
| NRTR | R31-1/16-1/8 | 0.9470 | 0.8918 | 0.9399 | 0.7376 | 0.7969 | 0.8854 | model | log | |
| NRTR-TTA | R31-1/16-1/8 | 0.9423 | 0.8903 | 0.9360 | 0.7641 | 0.8016 | 0.8854 |
We also provide NRTR trained on Union14M
Evaluated on six common benchmarks
| Methods | Backbone | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||||
| NRTR | R31-1/8-1/4 | 0.9673 | 0.9320 | 0.9557 | 0.8074 | 0.8357 | 0.9201 | model |
Evaluated on Union14M-Benchmark
| Methods | Backbone | Unsolved Challenges | Additional Challenges | General | download | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Curve | Multi-Oriented | Artistic | Contextless | Salient | Multi-Words | Incomplete | General | ||||
| NRTR | R31-1/8-1/4 | 0.493 | 0.406 | 0.543 | 0.696 | 0.429 | 0.755 | 0.015 | 0.752 | model |
Citation¶
@inproceedings{sheng2019nrtr,
title={NRTR: A no-recurrence sequence-to-sequence model for scene text recognition},
author={Sheng, Fenfen and Chen, Zhineng and Xu, Bo},
booktitle={2019 International Conference on Document Analysis and Recognition (ICDAR)},
pages={781--786},
year={2019},
organization={IEEE}
}
RobustScanner¶
RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition
Abstract¶
The attention-based encoder-decoder framework has recently achieved impressive results for scene text recognition, and many variants have emerged with improvements in recognition quality. However, it performs poorly on contextless texts (e.g., random character sequences) which is unacceptable in most of real application scenarios. In this paper, we first deeply investigate the decoding process of the decoder. We empirically find that a representative character-level sequence decoder utilizes not only context information but also positional information. Contextual information, which the existing approaches heavily rely on, causes the problem of attention drift. To suppress such side-effect, we propose a novel position enhancement branch, and dynamically fuse its outputs with those of the decoder attention module for scene text recognition. Specifically, it contains a position aware module to enable the encoder to output feature vectors encoding their own spatial positions, and an attention module to estimate glimpses using the positional clue (i.e., the current decoding time step) only. The dynamic fusion is conducted for more robust feature via an element-wise gate mechanism. Theoretically, our proposed method, dubbed \emph{RobustScanner}, decodes individual characters with dynamic ratio between context and positional clues, and utilizes more positional ones when the decoding sequences with scarce context, and thus is robust and practical. Empirically, it has achieved new state-of-the-art results on popular regular and irregular text recognition benchmarks while without much performance drop on contextless benchmarks, validating its robustness in both contextual and contextless application scenarios.

Dataset¶
Results and Models¶
| Methods | GPUs | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | ||||
| RobustScanner | 4 | 0.9510 | 0.9011 | 0.9320 | 0.7578 | 0.8078 | 0.8750 | model | log | |
| RobustScanner-TTA | 4 | 0.9487 | 0.9011 | 0.9261 | 0.7805 | 0.8124 | 0.8819 |
References¶
[1] Li, Hui and Wang, Peng and Shen, Chunhua and Zhang, Guyu. Show, attend and read: A simple and strong baseline for irregular text recognition. In AAAI 2019.
Citation¶
@inproceedings{yue2020robustscanner,
title={RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition},
author={Yue, Xiaoyu and Kuang, Zhanghui and Lin, Chenhao and Sun, Hongbin and Zhang, Wayne},
booktitle={European Conference on Computer Vision},
year={2020}
}
SAR¶
Show, Attend and Read: A Simple and Strong Baseline for Irregular Text Recognition
Abstract¶
Recognizing irregular text in natural scene images is challenging due to the large variance in text appearance, such as curvature, orientation and distortion. Most existing approaches rely heavily on sophisticated model designs and/or extra fine-grained annotations, which, to some extent, increase the difficulty in algorithm implementation and data collection. In this work, we propose an easy-to-implement strong baseline for irregular scene text recognition, using off-the-shelf neural network components and only word-level annotations. It is composed of a 31-layer ResNet, an LSTM-based encoder-decoder framework and a 2-dimensional attention module. Despite its simplicity, the proposed method is robust and achieves state-of-the-art performance on both regular and irregular scene text recognition benchmarks.

Dataset¶
Results and Models¶
| Methods | Backbone | Decoder | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | |||||
| SAR | R31-1/8-1/4 | ParallelSARDecoder | 0.9533 | 0.8964 | 0.9369 | 0.7602 | 0.8326 | 0.9062 | model | log | |
| SAR-TTA | R31-1/8-1/4 | ParallelSARDecoder | 0.9510 | 0.8964 | 0.9340 | 0.7862 | 0.8372 | 0.9132 | ||
| SAR | R31-1/8-1/4 | SequentialSARDecoder | 0.9553 | 0.9073 | 0.9409 | 0.7761 | 0.8093 | 0.8958 | model | log | |
| SAR-TTA | R31-1/8-1/4 | SequentialSARDecoder | 0.9530 | 0.9073 | 0.9389 | 0.8002 | 0.8124 | 0.9028 |
We also provide ASTER trained on Union14M
Evaluated on six common benchmarks
| Methods | Backbone | Decoder | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | |||||
| SAR | R31-1/8-1/4 | SequentialSARDecoder | 0.9707 | 0.9366 | 0.9576 | 0.8219 | 0.8698 | 0.9201 | model |
Evaluated on Union14M-Benchmark
| Methods | Backbone | Decoder | Unsolved Challenges | Additional Challenges | General | download | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Curve | Multi-Oriented | Artistic | Contextless | Salient | Multi-Words | Incomplete | General | |||||
| SAR | R31-1/8-1/4 | SequentialSARDecoder | 0.689 | 0.569 | 0.606 | 0.733 | 0.601 | 0.746 | 0.021 | 0.760 | model |
Citation¶
@inproceedings{li2019show,
title={Show, attend and read: A simple and strong baseline for irregular text recognition},
author={Li, Hui and Wang, Peng and Shen, Chunhua and Zhang, Guyu},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={33},
number={01},
pages={8610--8617},
year={2019}
}
SATRN¶
On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention
Abstract¶
Scene text recognition (STR) is the task of recognizing character sequences in natural scenes. While there have been great advances in STR methods, current methods still fail to recognize texts in arbitrary shapes, such as heavily curved or rotated texts, which are abundant in daily life (e.g. restaurant signs, product labels, company logos, etc). This paper introduces a novel architecture to recognizing texts of arbitrary shapes, named Self-Attention Text Recognition Network (SATRN), which is inspired by the Transformer. SATRN utilizes the self-attention mechanism to describe two-dimensional (2D) spatial dependencies of characters in a scene text image. Exploiting the full-graph propagation of self-attention, SATRN can recognize texts with arbitrary arrangements and large inter-character spacing. As a result, SATRN outperforms existing STR models by a large margin of 5.7 pp on average in “irregular text” benchmarks. We provide empirical analyses that illustrate the inner mechanisms and the extent to which the model is applicable (e.g. rotated and multi-line text). We will open-source the code.
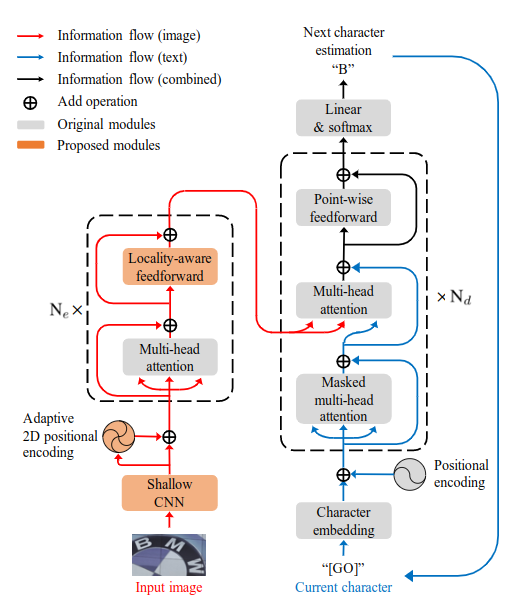
Dataset¶
Train Dataset¶
| trainset | instance_num | repeat_num | source |
|---|---|---|---|
| SynthText | 7266686 | 1 | synth |
| Syn90k | 8919273 | 1 | synth |
Test Dataset¶
| testset | instance_num | type |
|---|---|---|
| IIIT5K | 3000 | regular |
| SVT | 647 | regular |
| IC13 | 1015 | regular |
| IC15 | 2077 | irregular |
| SVTP | 645 | irregular |
| CT80 | 288 | irregular |
Results and Models¶
| Methods | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | |||
| Satrn | 0.9600 | 0.9181 | 0.9606 | 0.8045 | 0.8837 | 0.8993 | model | log | |
| Satrn-TTA | 0.9530 | 0.9181 | 0.9527 | 0.8276 | 0.8884 | 0.9028 | ||
| Satrn_small | 0.9423 | 0.9011 | 0.9567 | 0.7886 | 0.8574 | 0.8472 | model | log | |
| Satrn_small-TTA | 0.9380 | 0.8995 | 0.9488 | 0.8122 | 0.8620 | 0.8507 |
We also provide SATRN trained on Union14M
Evaluated on six common benchmarks
| Methods | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | |||
| SATRN | 0.9727 | 0.9536 | 0.9685 | 0.8714 | 0.9039 | 0.9618 | model |
Evaluated on Union14M-Benchmark
| Methods | Unsolved Challenges | Additional Challenges | General | download | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Curve | Multi-Oriented | Artistic | Contextless | Salient | Multi-Words | Incomplete | General | |||
| SATRN | 0.748 | 0.647 | 0.671 | 0.761 | 0.722 | 0.741 | 0.009 | 0.758 | model |
Citation¶
@article{junyeop2019recognizing,
title={On Recognizing Texts of Arbitrary Shapes with 2D Self-Attention},
author={Junyeop Lee, Sungrae Park, Jeonghun Baek, Seong Joon Oh, Seonghyeon Kim, Hwalsuk Lee},
year={2019}
}
SVTR¶
SVTR: Scene Text Recognition with a Single Visual Model
Abstract¶
Dominant scene text recognition models commonly contain two building blocks, a visual model for feature extraction and a sequence model for text transcription. This hybrid architecture, although accurate, is complex and less efficient. In this study, we propose a Single Visual model for Scene Text recognition within the patch-wise image tokenization framework, which dispenses with the sequential modeling entirely. The method, termed SVTR, firstly decomposes an image text into small patches named character components. Afterward, hierarchical stages are recurrently carried out by component-level mixing, merging and/or combining. Global and local mixing blocks are devised to perceive the inter-character and intra-character patterns, leading to a multi-grained character component perception. Thus, characters are recognized by a simple linear prediction. Experimental results on both English and Chinese scene text recognition tasks demonstrate the effectiveness of SVTR. SVTR-L (Large) achieves highly competitive accuracy in English and outperforms existing methods by a large margin in Chinese, while running faster. In addition, SVTR-T (Tiny) is an effective and much smaller model, which shows appealing speed at inference.

Dataset¶
Train Dataset¶
| trainset | instance_num | repeat_num | source |
|---|---|---|---|
| SynthText | 7266686 | 1 | synth |
| Syn90k | 8919273 | 1 | synth |
Test Dataset¶
| testset | instance_num | type |
|---|---|---|
| IIIT5K | 3000 | regular |
| SVT | 647 | regular |
| IC13 | 1015 | regular |
| IC15 | 2077 | irregular |
| SVTP | 645 | irregular |
| CT80 | 288 | irregular |
Results and Models¶
| Methods | Regular Text | Irregular Text | download | |||||
|---|---|---|---|---|---|---|---|---|
| IIIT5K | SVT | IC13-1015 | IC15-2077 | SVTP | CT80 | |||
| SVTR-tiny | - | - | - | - | - | - | - | |
| SVTR-small | 0.8553 | 0.9026 | 0.9448 | 0.7496 | 0.8496 | 0.8854 | model | log | |
| SVTR-small-TTA | 0.8397 | 0.8964 | 0.9241 | 0.7597 | 0.8124 | 0.8646 | ||
| SVTR-base | 0.8570 | 0.9181 | 0.9438 | 0.7448 | 0.8388 | 0.9028 | model | log | |
| SVTR-base-TTA | 0.8517 | 0.9011 | 0.9379 | 0.7569 | 0.8279 | 0.8819 | ||
| SVTR-large | - | - | - | - | - | - | - |
注解
The implementation and configuration follow the original code and paper, but there is still a gap between the reproduced results and the official ones. We appreciate any suggestions to improve its performance.
Citation¶
@inproceedings{ijcai2022p124,
title = {SVTR: Scene Text Recognition with a Single Visual Model},
author = {Du, Yongkun and Chen, Zhineng and Jia, Caiyan and Yin, Xiaoting and Zheng, Tianlun and Li, Chenxia and Du, Yuning and Jiang, Yu-Gang},
booktitle = {Proceedings of the Thirty-First International Joint Conference on
Artificial Intelligence, {IJCAI-22}},
publisher = {International Joint Conferences on Artificial Intelligence Organization},
editor = {Lud De Raedt},
pages = {884--890},
year = {2022},
month = {7},
note = {Main Track},
doi = {10.24963/ijcai.2022/124},
url = {https://doi.org/10.24963/ijcai.2022/124},
}